So long 2018, Hello 2019!

As we wrap up 2018, it’s a good time for us to take stock and look towards 2019. Verge Labs has had our best year ever (being our first year as well). We’ve got to work on some great projects, build out our product range of machine learning apps and got to speak at some amazing conferences. We’d like to thank all of our customers, partners and people we’ve been fortunate enough to work with this year. We’re looking forward to working with you on some more exciting projects next year!
That brings us to what we think are going to be some of the big ideas in machine learning in 2019:
Algorithmic Oversight
Investigating models in-depth will be a normal part of the modelling process. Things like model interpretability and bias/fairness considerations will be something all data scientists take into account when embarking on a project. It won’t just be for audit or compliance reasons. We believe people will want to do this in order to get as much information as possible out of the modelling process as possible, ensure that the model is behaving as expected and a way to make sure biases in society (and data) that we do not want aren’t captured in the model.
Intelligence Augmentation
Ok … so this isn’t a new idea, this month marks the 50th anniversary of Douglas Engelbert’s ‘Mother of All Demos’. But this idea of augmentation and helping people be more productive and make better decisions is well aligned with where machine learning is heading. A lot of people are not comfortable with completely automating a process and still want to be in control and responsible for the outcomes. Human-in-the-loop and Active Learning systems will allow people to leverage not only their own knowledge but also insights from artificial intelligence.
JavaScript goes legit (for Machine Learning)
You could make the argument that JavaScript is the next big language for data science. It has all the components already;
- Visualisation, there are some brilliant data visualisation libraries available in JS such as d3, leaflet, deck.gl and three.js
- Data Manipulation, d3 is not only great for visualisation, but also data manipulation and wrangling
- Notebooks, if you haven’t already, go check out Observable, it’s a brilliant notebook environment for doing and sharing data analysis
- Modelling, Tensorflow.js is a surprisingly rich library with the ability to train models and also use them from a browser
And best of all, JavaScript is ubiquitous, all someone needs to start analysing some data is a web browser.
VR & AR with ML
VR (Virtual Reality) and AR (Augmented Reality) are poised to have a big impact in 2019. There’s main stream adoption in the gaming space with many options available on the market at a reasonable price point. Add to that, mobile devices like iPhone and Android phones have the capability for AR development. There’s a few different ways where machine learning can come into play, including object detection to be able to overlay information about an object, e.g. nutritional information of food products. There’s also the possibility of immersive data visualisation, allowing the user to explore spatial or high dimensional data in a fun, interactive experience. There’s some research already being done in this space that we are expecting to see adopted in the near future.
Private Machine Learning (Federated Learning)
An important consideration for sensitive information is private machine learning. People are becoming more aware of their data being sold and wanting some level of data privacy. That doesn’t mean they have to miss out on the benefits of machine learning. Federated learning can be a solution to using private information in models by doing the model training on the device (e.g. a mobile phone), and not uploading any of a user’s private data. For a more in depth review on the topic look at OpenMined.
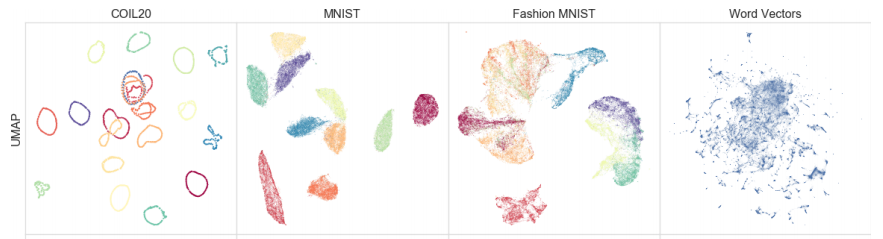
UMAP is added to everyone’s toolkit
UMAP (Uniform Manifold And Projection for Dimension Reduction) is a topological data analysis tool for dimensionality reduction and can be a great way to explore and understand data. It produces useful visualisations (like the one below) and you can then use the embeddings later in the modelling phase. You can see the paper here and find the code for implementing it in Python here.
And that’s it from us for 2018! Thanks for reading the blog throughout the year - we’ve received some positive feedback and will continue to share all the latest and greatest in ML and AI in 2019 🚀 if you’ve got your own predictions, let us know on Twitter or LinkedIn.