The Notebook Ecosystem

Notebooks - More than just Moleskins
Notebooks are an interactive environment for analysing data with the ability to write code, run code and document it. They’re popular amongst data scientist because it’s an easy way to quickly iterate through ideas and share with others. There’s also some extensions being developed (covered later in this article) that allows notebooks to be used in a production environment rather than just for ad-hoc analysis.
The main notebooks people think of when they are talking about notebooks are Jupyter, which stands for Julia, Python, R. There are also other languages that can be used within the notebook as well. These are known as kernels - the ‘computational engine’ that runs the code in the notebook. We specify the language (e.g. R or Python) and the version (e.g. Python 2.7 or Python 3.6) we want to use by setting the kernel. Also, one other thing about Jupyter, it was built from a Python specific notebook format called iPython, which is why you see Jupyter notebooks saved with an “.ipynb” extension.
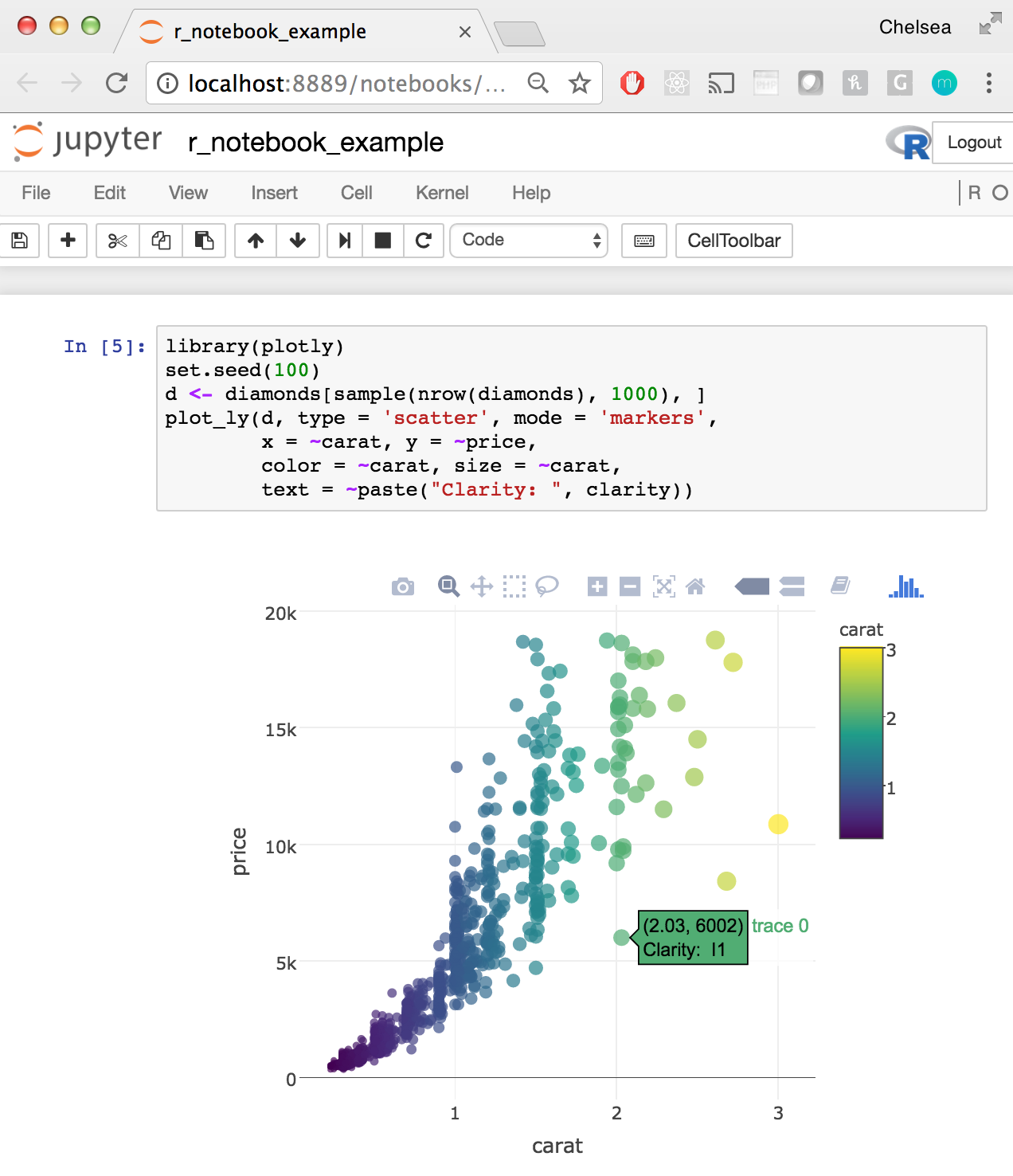 An example of a Jupyter Notebook
An example of a Jupyter Notebook
Notebooks aren’t just for code though, you can also insert nicely formatted documentation in the notebook itself. We might want to document what’s happening in our notebook, rather than just writing comments in our code (which we should still be doing). This type of documentation is there to write the narrative around the analysis, so people that might not be able to read the code can still follow the work being done. The formatting is done through a lightweight language called markdown. Think of markdown as a way to code what sections of text should be a header, or in italics, or in a list, etc. See this Github tutorial for a good guide to markdown.
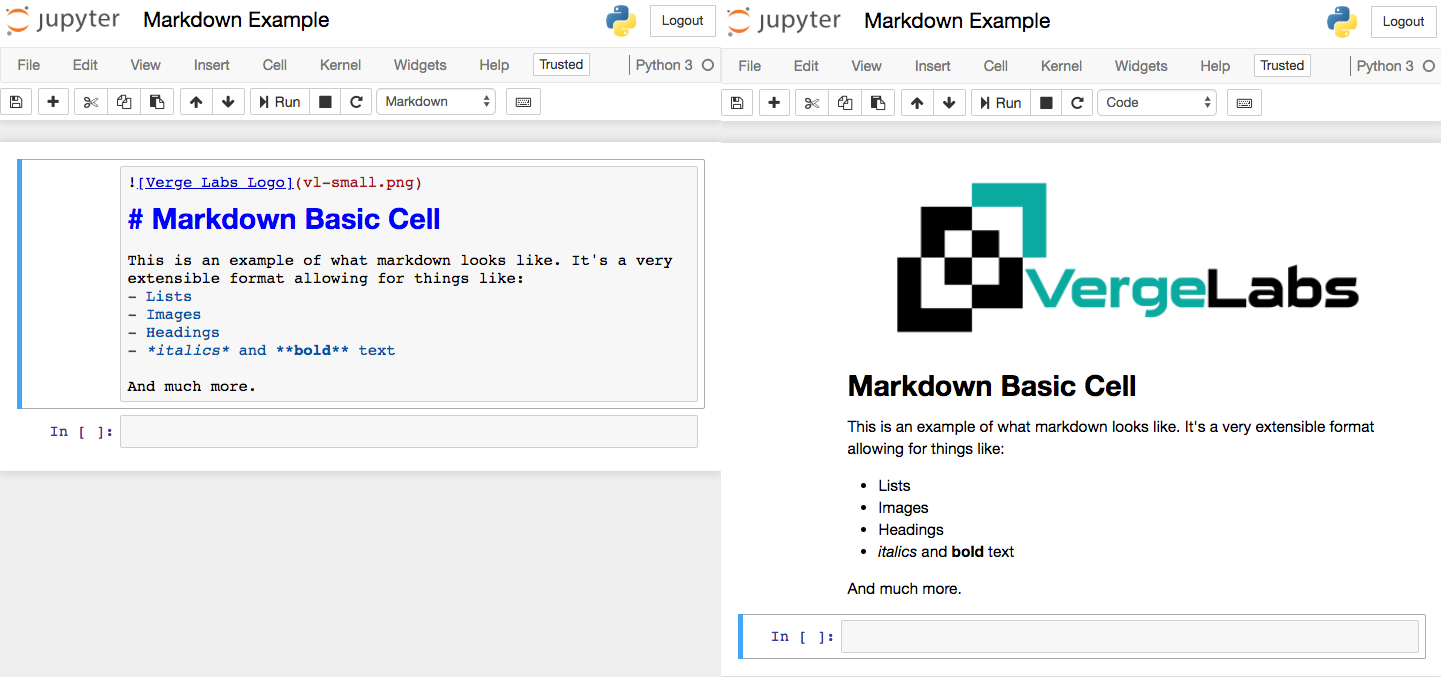 Producing formatted documentation with markdown
Producing formatted documentation with markdown
Why use notebooks?
A big advantage of notebooks over just coding is the ability to explain in English (or another natural language), what the program is doing. This is a style of programming known as ’literate programming’ introduced by Donald Knuth. Literate programming encourages the data scientist to explain the thought process behind the analysis, which in turn makes poorly planned projects or incorrect assumptions easier to pick up. The audience for a notebook could be another person like a work colleague but it might also be the same data scientist revisiting the analysis in the future. I know I’ve looked at some code I’ve written at a later date and can’t remember the details - that’s when knowing what the data scientist is thinking is useful - even if it is yourself.
Notebooks are also handy to have as a teaching tool. It’s fairly easy to get started and running code, especially using something like Anaconda, which packages all the required programs into one bundle that’s easy to install. From there it’s a case of providing students with useful notebooks that can serve as templates for later projects. Some people might look down on the cookie cutter approach but learning to code can be modifying bits of code that are known to run correctly. Although, keep in mind, when creating notebooks for teaching it’s important not to have entire lessons that can be solved by running cell after cell without any other type of input.
Finally, we are seeing more companies adopt notebooks as part of their production environment for machine learning and data science. Notebooks have always been great for ad-hoc and exploration work, but some care needs to be taken when trying to turn a notebook into a repeatable and reproducible procedure. Now, with a developing ecosystem of infrastructure around notebooks, the process of turning an ad-hoc notebook analysis into something which can be re-used and relied on is getting a lot easier.
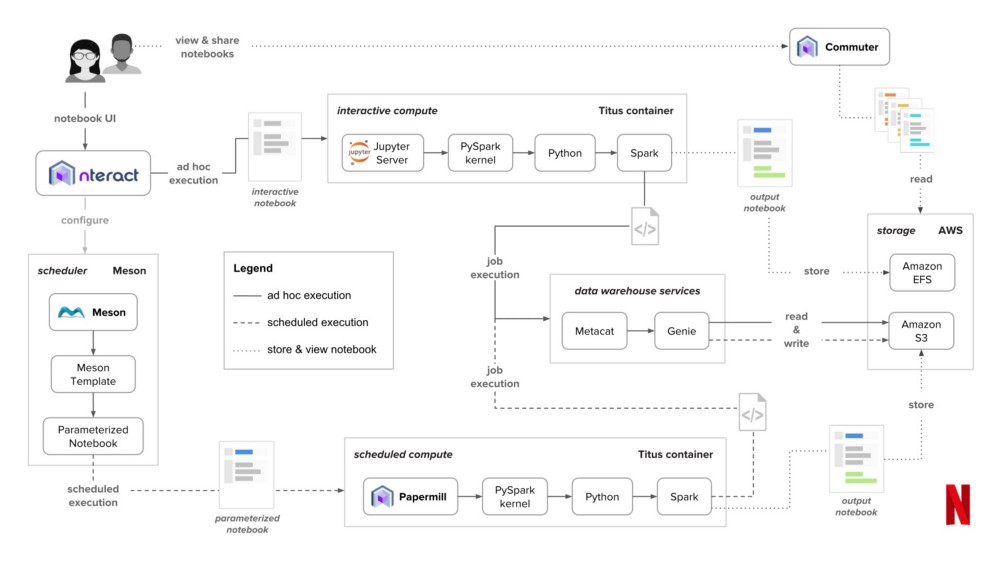 How Netflix uses notebooks in production
How Netflix uses notebooks in production
Extending the Notebook Ecosystem
There’s been some great extensions to notebooks over the past year, including new types of notebooks, free virtual machines to run them on and using them in a machine learning pipeline.
Some of the most popular extensions to Jupyter have included JupyterHub and JupyterLab. JupyterHub is a way to manage multiple notebook users on the one server. It allows teams of data scientists to work off a secure environment and gives them access to their own workspace and shared resources. JupyterLab is the next generation of notebooks and offers something closer to an Integrated Developer Environment (IDE) for data scientists.
There are also notebooks other than Jupyter built primarily for languages other than Python. This includes Zepplin for Spark and Rstudio’s notebook interface through Rmarkdown for R. One of the most interesting versions of notebooks that isn’t Jupyter, is Observable. These are notebooks for javascript that run entirely in the browser. One of the things that these notebooks highlight is that javascript is becoming a fully fledged language for data science with libraries for data manipulation (d3), visualisation (d3, leaflet, three.js, deck.gl) and modelling (tensorflow.js). Observable is also a reactive notebook, meaning that as you make changes to the cells, anything that depends on those values is also updated. This helps make sure thing are executed in the right order and the code becomes a bit easier to track.
Another great development related to notebooks has been being able to run them for free in places like Google Colab, Kaggle Kernels, Azure Notebooks and Binder. These services allow you to run a notebook for free on hosted infrastructure (or in the case of Colab a mix of your local machine and their infrastructure). Each service has a slightly different offering with respect to RAM, GPU access and languages available (see table below for more details). If you’re just getting started I’d recommend checking out Kaggle Kernels, they have some great examples and a good sized machine to run your notebooks on. It’s also worth mentioning Google Colab, which has some advanced examples published through Distill (a great online machine learning journal) and the Tensorflow documentation.
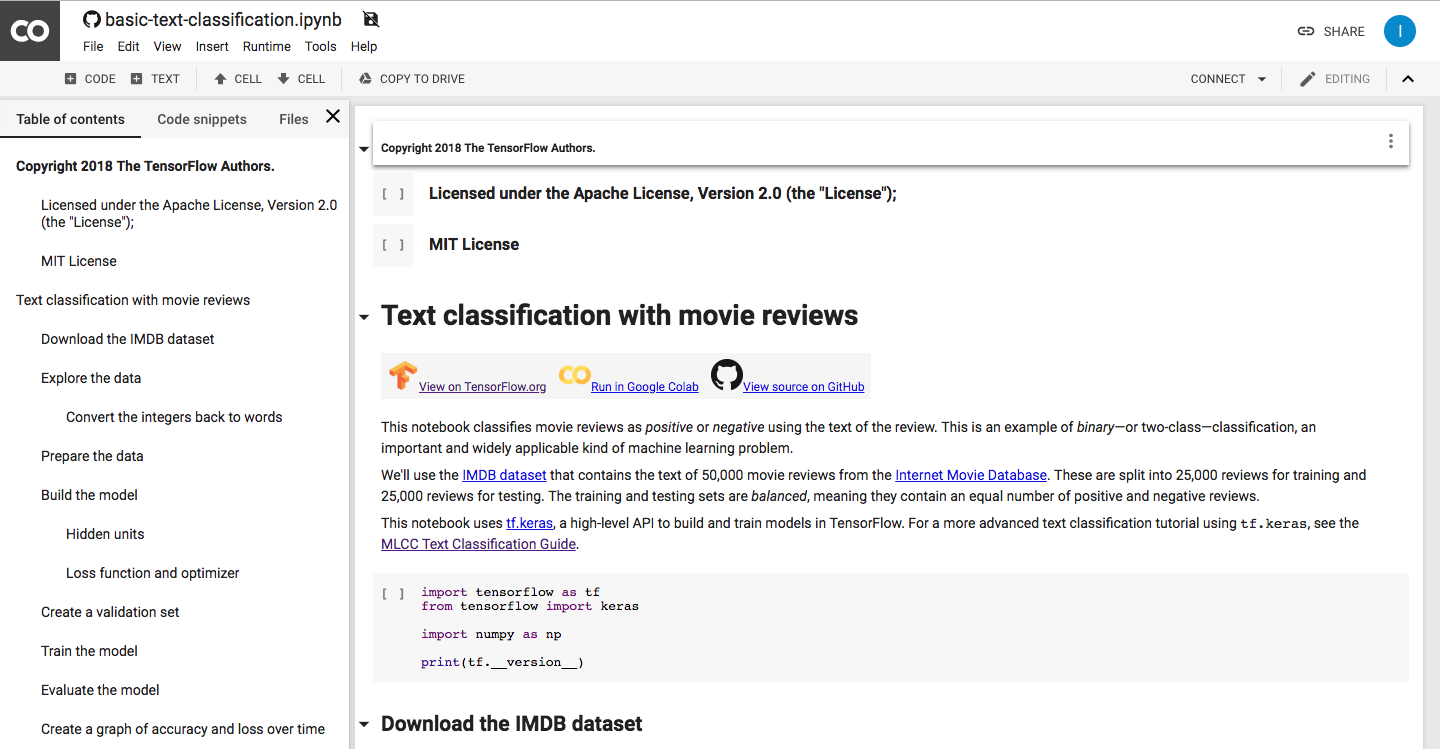 An example of a Tensorflow tutorial in Google Colab
An example of a Tensorflow tutorial in Google Colab
Some of the cutting edge work with notebooks is providing users with a way to integrate notebooks into a reliable machine learning pipeline. This includes the ability to schedule notebooks, save and manage results and also serve models after they’ve been trained. There are open source programs like nteract and papermill that allow you to manage the pipeline for yourself. There are also managed services like AWS Sagemaker, Domo Labs and Paperless.
Below is a quick summary of the ecosystem, what they provide and what they can be used for.
| Name | Environment | Memory | GPU | Cost | Languages | Summary |
|---|---|---|---|---|---|---|
| Jupyter | 💻 ➕ ☁️ | ❓ | ❓ | 👌 | Julia, Python, R and many others | One of the most popular notebook formats. |
| R Notebooks | 💻 ➕ ☁️ | ❓ | ❓ | 👌 | R, Python, Javascript and others | Notebooks primarily built for R |
| Zepplin | 💻 ➕ ☁️ | ❓ | ❓ | 👌 | Spark, SQL & Python | Notebooks primarily built for Spark |
| Observable | 💻 ➕ ☁️ | ❓ | ❓ | 👌 | Javascript | Reactive javascript notebooks 👍 |
| nteract | 💻 ➕ ☁️ | ❓ | ❓ | 👌 | Julia, Python, R and many others | Intuitive and approachable desktop app for notebooks |
| JupyterHub | 💻 ➕ ☁️ | ❓ | ❓ | 👌 | Julia, Python, R and many others | Multi User Server for Jupyter notebooks |
| JupyterLab | 💻 ➕ ☁️ | ❓ | ❓ | 👌 | Julia, Python, R and many others | Next generation of Jupyter notebooks |
| Papermill | 💻 ➕ ☁️ | ❓ | ❓ | 👌 | Python, R | Parameterise, execute, and analyse Jupyter Notebooks |
| Google Colab | 💻 ➕ ☁️ | 13 GB | ✅ | 👌 | Python | Great Jupyter notebook environment that connects to Google Drive |
| Kaggle Kernels | ☁️ | 17 GB | ✅ | 👌 | Python, R | Excellent place to learn from other people and run notebooks |
| Azure Notebooks | ☁️ | 4 GB | ❌ | 👌 | Python, R, F# | Coding in browser and links to the Azure cloud environment |
| Binder | ☁️ | 2 GB | ❌ | 👌 | Julia, Python, R and many others | One of the first places to run notebooks online |
| AWS Sagemaker | 💻 ➕ ☁️ | ❓ | ❓ | 💲 | Python | Build, train, and deploy machine learning models at scale on AWS |
| Domino labs | ☁️ | ❓ | ❓ | 💲 | Julia, Python, R and many others | Managed data science environment with notebooks |
| Paperspace | ☁️ | ❓ | ❓ | 💲 | Python, R | Managed data science notebook environments |
❓ - Depends on your machine or configuration
Some things to watch out for
As great as notebooks are there are some things to watch out for when using them:
- executing things out of order: try and run things top down and keep an eye on the numbers in the margin which indicate what order the cells were executed in
- hidden execution: don’t remove cells that have been previously run
- when using them for teaching: avoid having sessions that can be completed just by running each cell, make sure the user has to think in order to complete the lesson
See a good summary of things to watch out for here. Keep in mind, not all notebooks share these issues. Notebooks like Observable encourage users to do avoid some of these issues through their design.
To wrap it up we’ve covered. what notebooks are, why they are popular with data scientists and some of the extensions being developed (looking beyond just the Jupyter ecosystem). If you want to find out more on notebooks, have a look at these articles:
- Atlantic - The Scientific Paper is Obsolete
- Observable - Introduction to Notebooks
- Text Classification in Google Colab
If you enjoyed the article, or think we’ve missed anything - let us know on Twitter or LinkedIn. (Thanks to Kyle Kelley for doing so and correcting the info in the table).